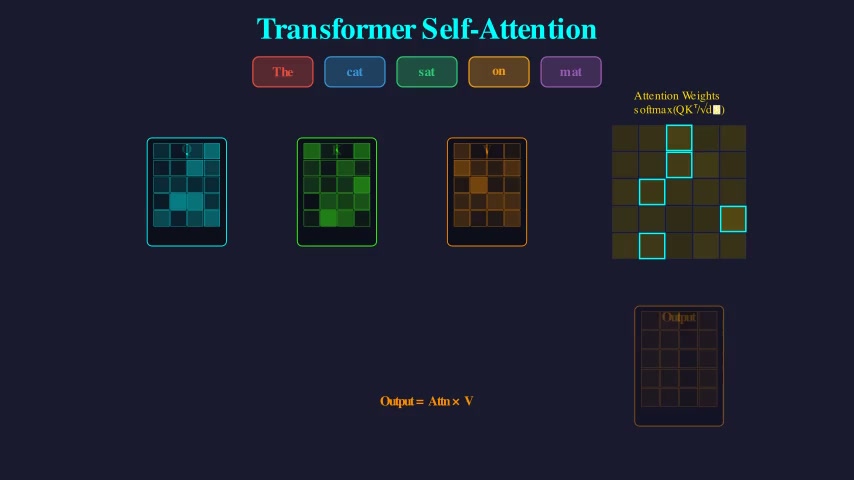
Transformer Self-Attention
Visualizes the scaled dot-product self-attention mechanism in a Transformer. Input tokens are projected to Q, K, V matrices, attention scores are computed via Q×K^T dot products shown as a heatmap, softmax is applied, and the output is computed as a weighted sum with V. The full attention formula is displayed.